Some say dogs are humans best friend. I myself once had a Border Collie half-breed which people often confused for a Labrador Retriever. I had no hard feelings when people told me: “This is the cutest Labrador I have ever seen!”. Sometimes it is really hard to distinguish certain breeds. It comes down to minor differences which are hard to detect.
In this post we will try to implement an algorithmic approach that helps me to name the breed of a dog based on an image. To make things a little bit more fun the algorithm will also distinguish between humans and dogs. If a human is detected, it will provide an estimate of the dog breed that is most resembling. This project is part of the Udacity Data Science Nanodegree and the code of this project can be found on Github.

Detecting dogs and humans
As so often it is not necessary to start completely from scratch. In order to decide whether an image contains a human or not we can use the Haar feature-based cascade classifiers. This classifier from OpenCV is a pre-trained face detectors and will help us to identify humans in pictures. With minimal effort we can implement a function face_detector which will return TRUE if a face is detected and FALSE if not.
While this is a relatively straight forward approach it is a little bit trickier to find a way of detecting dogs in images. One way to identify dogs is to use a pre-trained ResNet-50 model. In Keras it is possible to load the ResNet-50 model, along with weights that have been trained on ImageNet, a very large, very popular dataset used for image classification and other vision tasks. An image in this classification task contains an object from on of 1000 categories.
When you exanimate these 1000 categories you will notice that the categories corresponding to dogs appear in an uninterrupted sequence and correspond to dictionary keys 151-268, inclusive, to include all categories from 'Chihuahua' to 'Mexican hairless'. With this knowledge we can write a function dog_detector which returns TRUE if the predicted label for an image is between 151 and 268.
Create a CNN from scratch
Now that we implemented the face_detector and the dog_detector we can go ahead and create a CNN from scratch. Without using transfer learning the network certainly will not achieve great scores (the target from Udacity is to achieve 1% accuracy on the test set). The next picture shows the first architecture I found that exceeded the minimal requirements after 5 training epochs.
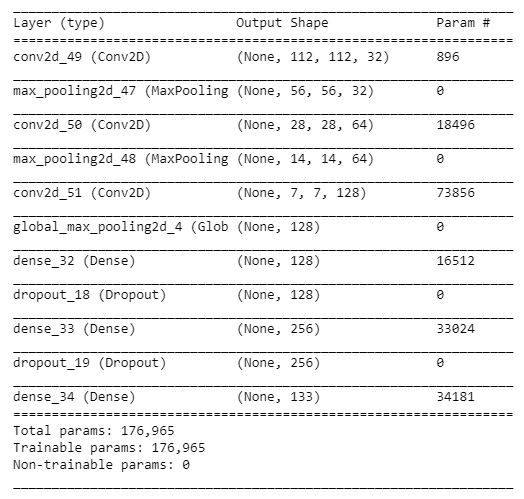
What you can see in the model summary is that I used three convolution + pooling layers. I set the number of filters of the first convolution layer to 32 and doubled the parameter for each subsequent convolution. To reduce the dimensionality and to therefore keeping the number of parameters low I decided to set the stride parameter to (2,2). The max pooling layers are used for the same reasons. Furthermore I added two fully connected layers with 128 neurons and a dropout layer after each of them to reduce overfitting. In the model summary you can also see some additional information which I left out by now (e.g. the images get resized to 224x224, and the number of classes is 133).
This network achieves ~1% accuracy on the test set and is therefore just barely better then guessing.
CNN with transfer learning
It took me some time and fiddling (adding some layers, changing the kernel size, etc.) to just achieve the 1% accuracy when starting from scratch. In this section we will use bottleneck features from three very famous CNN networks to help us with the classification task. With this transfer learning technique we will reduce training time and hopefully improve our test accuracy without having to worry about the right architecture components and parameters. We will use the pre-computed features from the networks VGG-16, ResNet-50 and Inception.
The last convolutional output of all of these three pre-trained models will be fed as input to a fixed architecture setting. We only add a global average pooling layer, a fully connected layer and a dropout layer to retrieve three comparable architectures which use different pre-trained models. Now we will train these networks for 20 epochs and compare their results. The following plot shows the validation accuracy over the training epochs for the VGG-19, ResNet-50 and Inception network respectively.
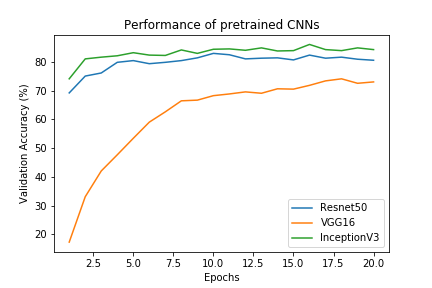
As seen in the plot the Inception bottleneck features provide the best validation accuracy, closely followed by the ResNet-50. Also both of these networks start with relatively high accuracy’s right out of the box.
I assume that has something to do with the classes the networks were trained on originally. Both the Inception and the ResNet-50 seem to have prior knowledge about dog breeds while the VGG-19 has to start from “scratch” (if you have a different interpretation of this feel free to contact me). If this assumption holds, the VGG-19 could be trained for a little bit longer to guarantee that the conditions are equal for all networks.
Next we will take a closer look at the training and validation loss of the networks to see if or when overfitting occurs.
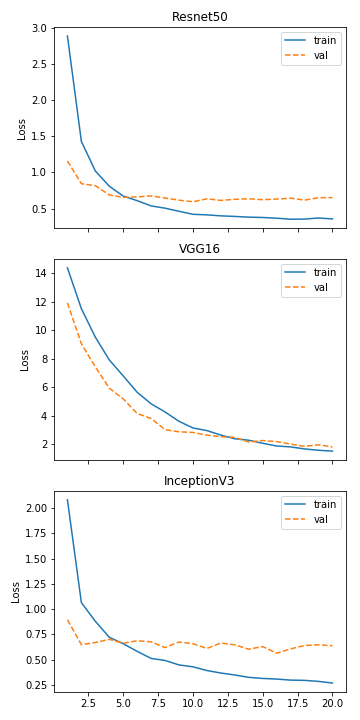
For both the ResNet50 and the Inception network overfitting begins really early. At around 5 epochs both architectures start overfitting on the validation set. The VGG16 architecture however, is starting to overfit much later at around 15 epochs.
There are certainly additional ways of regularizing the networks to prevent overfitting. In this post however I will leave it at that. The performance measures on the test set are comparable to the already shown metrics on the validation set.
Image classifier algorithm
With a test accuracy of ~ 82% the Inception network achieved quite satisfactory results on the test set. We will use this network to implement an algorithm that accepts any kind of picture and first determines whether the image contains a human, dog, or neither. Then,
- if a dog is detected in the image, return the predicted breed.
- if a human is detected in the image, return the resembling dog breed.
- if neither is detected in the image, provide output that indicates an error.
To check whether a dog or a human is detected we use the corresponding methods face_detector and dog_detector. If both return FALSE (indicating that neither a human nor a dog has been detected) an error will be printed.
I initially tested the algorithm with some fairly normal dog photos from the web and the results were almost always acceptable (meaning often it was the right breed or at least a very similar one). Feel free to try out some dog photos as well if you are using the Github code.
The final pictures which I included in this post are however more uncommon images. These help to highlight some of the weaknesses of the algorithm. I included pictures of Trump, Obama, Lassie, Scooby doo and a normal dog. Let’s see what the algorithm has to say to the images.

The first two pictures show photos of normal dogs. Even though the prediction for the images isn’t right (it is Pug and Rottweiler) a quick google search will show you that the predicted breeds look a lot like the actual ones.
The third picture (Scooby Doo) shows that neither the dog_detector nor the classification algorithm work for comic pictures. This makes sense since the training data only contains real images of dogs (these differ in texture, color, etc.).
The president cases show the fun side of the algorithm and I think the predictions are quite accurate.
The last case (Lassie) is a true positive in terms of the classification algorithm but it seems that the portrayal of Lassie is so human-like that the face_detector results in a false positive.
Improvements
To underline that the presented algorithm is far from being perfect I will highlight three aspects that could be improved (there are certainly more than three):
- human & dog detectors: I chose not to implement own human and dog detectors because I wanted to focus on the CNN part. Nevertheless I think that there is room for improvement here. It would be very cool (and I think promising) to train another CNN which has the job to classify the data into human vs non-human.
- parameter tuning: Even though I compared the different bottleneck features I spend little time on actually improving the architecture or the training parameters. Here different learning rates, number of layers, number of neurons, etc. could be tested to see if they impact the accuracy.
- fine tuning: rather then chosing either training from scratch or incorporating pretrained models (and just training the last layers) it could be tested if a more sophisticated fine tuning step could improve the performance metrics. This means “unfreazing” some of the top layers of the pretrained model to let the model adapt to the data it currently sees. There is a nice tensorflow tutorial that deals with this matter (click here)
Conclusion
In this blog post we saw how transfer learning can be used to boost your results. We jump from predicting roughly 1% of the dog breeds right to 80% just with using pre-trained models and spending (almost) no time on customizing the architecture. It isn’t always necessary to start completely from scratch when you can stand on the shoulders of giants.
Feel free to check out the corresponding Github repo to:
find out what’s your dog breed!